Why semantics matter: or how to build smart machines using OPC UA
by Wim Pessemier, R&D engineer at KU Leuven
While OPC UA today is mostly recognized for its communication virtues (regarding scalability, security, perfomance, platform-independence), one of it’s most exciting features remains in the shadows. Information modeling, or the ability to express not only data but also the meaning of data, is a key concept in the quest to make systems more intelligent, more autonomous and more evolvable. While the full potential of information modeling in industrial applications remains to be demonstrated by academic research, many of its core ideas can be applied right now.
1. Background: what’s an information model?
To understand better the ideas behind OPC UA information modeling, we first consider a general example of an information model (generally called semantic model), not specific to OPC UA applications. Fig. 1 shows the information model of two electric connectors (“plugX” and “socketY”), which are mechanically joined, and which contain two electrical contacts. We can see how “plugX” represents a plug, not because we named it this way, but because we have related it to the concept of Plug. While textual information such as “plugX” cannot easily be understood by a machine (i.e. it takes a human being to interpret this name), any machine that is a priori aware of the concept Plug and the relationship hasType will understand the nature of the “plugX” element – regardless of how it is called. Information models thus allow us to share contextual information in a machine-understandable way.
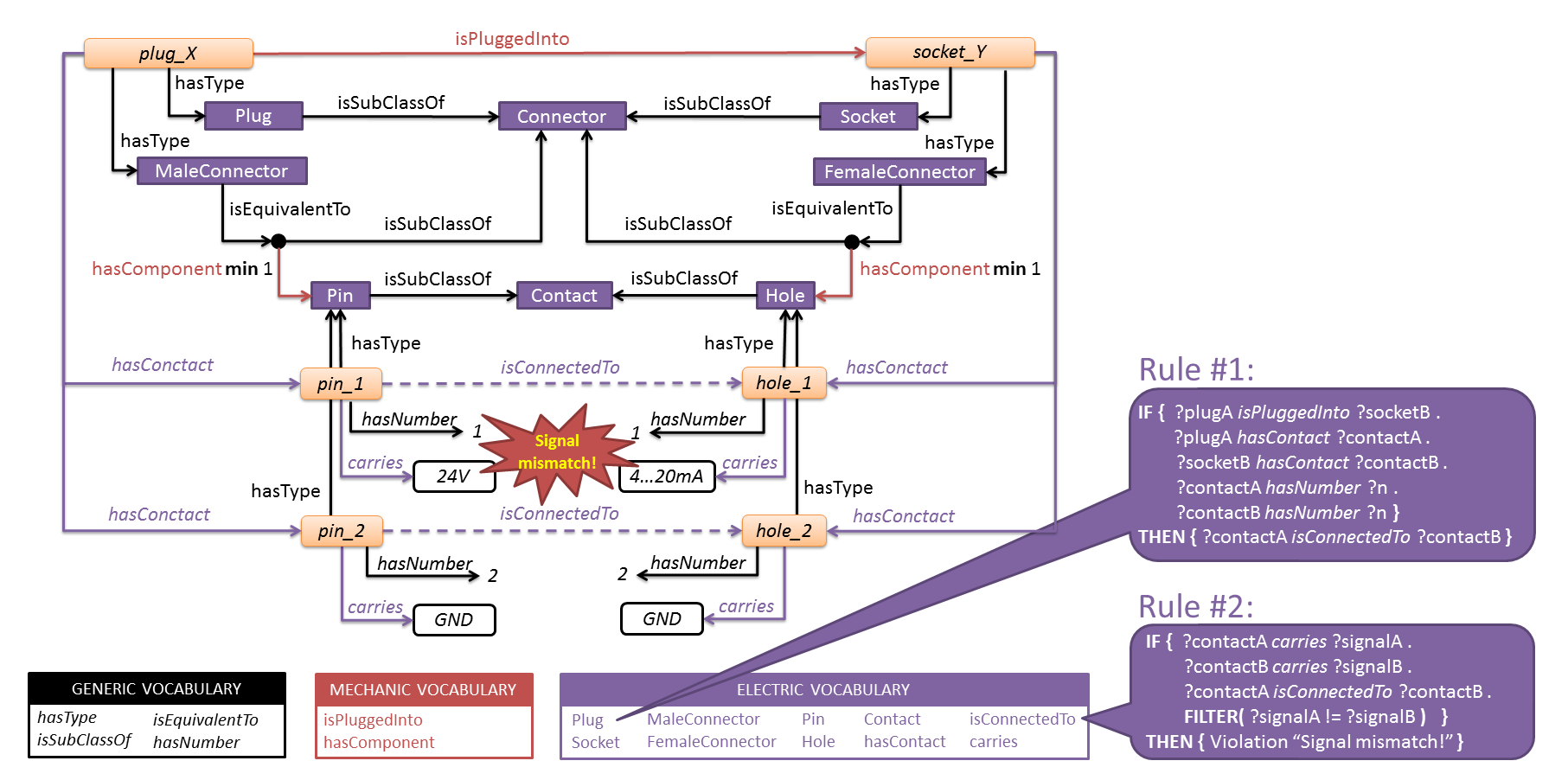 Fig. 1: General example of an information model.
Fig. 1: General example of an information model.
Information models can furthermore constrain the meaning (semantics) of the exposed data. For instance, we can see that “plugX” is not only a Plug but also a MaleConnector, which is defined according to the model as the “equivalent of a Connector having at least one Pin”. Exposing this kind of background knowledge can be very valuable, as it limits the number of (false) interpretations of the information. In this case, we note that the interpretation of concepts such as Plug, Socket, MaleConnector, FemaleConnector, … can be a source of confusion, despite their seamingly “evident” meaning. Contrary to textual descriptions in natural language, the definition of MaleConnector as shown in Fig. 1 can be unambiguously interpreted by software, provided that the software is sufficiently “smart” to interpret cardinality restrictions such as “min 1”. Information models thus allow us to constrain the meaning (semantics) of the exposed information, again in a way that can be understood by machines.
Finally, because the information captured by an information model is unambiguously described in a machine-understandable way, artificially intelligent (“smart”) software is able to reason about this model. New facts can be derived (“inferred”) automatically from an existing information model, or existing facts can be verified. For instance, Rule #1 in Fig. 1 says that “if two connectors are mechanically joined, then their correspondingly numbered electric contacts will be electrically connected to each other”. Thus, instead of manually adding the dashed relations in the model (see figure), a “smart” piece of software can derive these relations automatically. Similarly, by applying Rule #2 (saying that “two contacts that are electrically connected to each other, must carry the same signal”), the same software would be able to spot a “signal mismatch” in the given example. This example is of course mainly educational: it is very simple and it is able to solve just one particular problem in the field of electric engineering. Despite its simplicity though, it does have the potential to scale to very large electric systems consisting of many thousands of signals, which are impossible to reason about or to verify manually. And therein lies another advantage of information models: they can describe information in such a way that conclusions may be drawn fully automatically, by “smart” software, in order to solve a particular problem.
2. An inspiring application area: the Semantic Web
Before focusing on industrial applications of information models, one important – and very inspiring – application area of information models is worth mentioning. The Semantic Web is a visionary idea of a future World Wide Web, in which all information may be linked to each other, and in which all information may be processed by machines. It is a vision of the internet being a single information model, instead of the vast collection of data that is nowadays embedded in web pages as natural language text, or as meaningless (context-less) data. The latter “web of documents”, as the internet stands for today, can be read (via a web-browser), navigated (via hyperlinks) and searched (via search engines) – in natural language only. Indeed it takes a human being to search for some keywords, to browse the many relevant and the many more irrelevant search results, to skim through the displayed text, in order to find and aggregate the information needed to solve a task. In contrast, if the Web were to be an information model, a single query could return only the needed information in a machine understandable way, in order to solve the same task fully automatically. “Intelligent agents” could autonomously query the web, aggregate the results, reason about them, and act accordingly. While this idea is still far from being globally realized, the W3C and Semantic Web community have produced standards (RDF, RDFS, OWL, SPARQL, …) and a large number of tools to efficiently create, store and query information models consisting of millions of facts. Today Semantic Web technology is used by organizations in a wide variety of industries, essentially to make the best possible use of the vast data stores that they possess.
3. OPC UA: cornerstone of the semantic control system
Despite their success in various industries, Semantic Web technologies do not thrive well at the plant floor level, as they were simply not designed to meet the performance and scalability requirements of modern industrial control systems. Still, many of the core ideas behind the Semantic Web and OPC UA are very similar. Keeping the successful applications of Semantic Web technology at the enterprise level in mind, we list some of the most promising features of OPC UA:
- A language for information modeling
Apart from communication services and infrastructure components, OPC UA defines a language in which information models can be expressed. It allows us to expose not just data, but also the context of this data. Due to the contextual information, well designed information models are self-descriptive. Therefore, an OPC UA server address space doesn’t necessarily require an accompanying reference manual to be understood, because the meaning of the exposed data should be clear from the model itself. Not because of the way the OPC UA model elements are named (since this textual information can be interpreted by human beings only!), but instead because of the way the OPC UA model elements are linked to each other (since this information can be understood by machines). - A means to organize data
Information models such as shown in Fig. 1 appear to be very “unorganized”, yet a better way to look at them is to see them as being organized in several ways. Information models are unrestricted in the sense that any element (called a node in OPC UA terminology) of the model may be linked to any other element. It means that a single sensor data point may be linked to physical plant model elements (buildings, floors, cabinets, …), but also to software model elements (function blocks, programs, variables, …), to electric model elements (sensors, I/O modules, PLCs, …), and so on. By showing only the links of a particular domain (and hiding all the others), an electric engineer and a software engineer may therefore navigate through the same model in a different way. OPC UA supports Views for this purpose. Since all OPC UA nodes are uniquely identifiable and can therefore be linked to each other, there is no need to “copy” information twice in the same model. This is a big advantage of information models: all information needs to be specified only once. - A tool to find the right data
While the current World Wide Web can only be browsed by human beings clicking on hyperlinks, the Semantic Web can be browsed by machines that simply have to “follow” the links between the nodes of the global information model. OPC UA supports a very similar browsing experience via the Browse service. A client may browse the information exposed by one or multiple OPC UA servers just by following the links between the nodes. Ideally, this client should only care about the meaning (semantics) of the links, and not about “technical details” such as the names of the OPC UA nodes, or the connection details of the servers that host them. Software frameworks such as our in-house developed UAF offer such a “web browsing” experience. Support for queries has also been standardized by OPC UA, although this service appears to have few implementations today. However, as OPC UA address spaces are becoming larger and more complex, the Query service may become as useful for control systems tomorrow as search engines are for the (Semantic) Web today. For instance, a query such as “Select those temperature sensors related to system X that have a value above 50 degrees Celsius, list their physical location, and list the telephone numbers of the maintenance engineers that are responsible for them” would be very easy to express in the Semantic Web query language (SPARQL). OPC UA has the potential to bring this kind of useful queries – which are very common in the Semantic Web world – to the plant floor. - A way to build intelligent machines
The ability of a machine to unambiguously expose data and contextual information in a machine-understandable way, is a very powerful one. Not only does it allow other machines to interpret the exposed information correctly, but it also allows other machines to reason about the information and act accordingly. Accurately defined semantics are crucial in this case, because – unlike a human being – a machine cannot simply guess the meaning of some information if it’s not well defined, let alone decide what to do with it. It means that one of the biggest challenges to build intelligent machines (or “agents” in Semantic Web terminology) is not of technical nature. Because “technical concerns” (such as communication protocols, services, infrastructure components, …) are already taken care of by the OPC UA standard and available tools, what remains to be done is the modeling part. In other words, OPC UA offers a language to express and to exchange information, but the “vocabulary” of this language is at least as important if we want intelligent machines to do something useful with this information. Fortunately OPC UA already defines some base vocabulary that allow users to express for instance parent-child relationships (HasChild), instance-type relationships (HasTypeDefinition), type-subtype relationships (HasSubType), and so on. So-called “OPC UA companion specifications” extend this base vocabulary, for instance with a vocabulary to express alarms. Intelligent machines that monitor OPC UA alarms can therefore “understand” why a certain alarm was generated (by following the HasCause relation), or what its effects are (by following the HasEffect relation). Other companion specifications allow the meaningful definition of ISA-95 information, of PLCopen-compliant software models, and so on. Still, the semantics of these existing standards are often not sufficiently formal to allow intelligent machines to reason about them, in order to solve a task autonomously. For this to happen, the vocabularies must evolve into so-called ontologies, which contain much more strict definitions. Ontologies do not simply list concepts such as “MaleConnector”, but they add constraints such as “MaleConnector isEquivalentTo (Connector and (hasComponent min 1 Pin))”. Or they say that the electric “isConnectedTo” relationship is a symmetric one, meaning that if “A isConnectedTo B” then also “B isConnectedTo A”. Adding this kind of “smartness” to our models is very useful, as it allows artificially intelligent machines to correctly interpret the exposed information and autonomously do something with it. With the right semantics, machines can query each other (“Hey, what kind of services do you provide? What are your interfaces? What are your capabilities?”), and interact more efficiently and autonomously. In a world of the Internet of Things (IoT), semantic technologies such as OPC UA can play a decisive role, as they offer the framework to exchange this kind of well-defined information. As the many practical applications of the Semantic Web have proven, this is not a utopian, far-away dream. Today OPC UA represents a huge step towards Artifically Intelligent machines… it is time to take full use of it!
4. Application report: a knowledge-based control system for the Mercator Telescope
At the Canary Island of La Palma, on the edge of a caldera at 2300m above sea level, lies one of the most important astronomical observatories of the Norhern hemisphere: the Roque de los Muchachos Observatory. It is the home of the Mercator Telescope (Fig. 2), developed and operated by the University of Leuven (KU Leuven, Belgium). As part of a research project, the control system of this telescope is currently being refurbished, in coorperation with the department of electrical engineering (ESAT) of the KU Leuven. This new control system is fully “knowledge-based”: all engineering information that is needed throughout the whole development process is captured by information models. System designs (including models of requirements, constraints, verification tests, …), electrical designs (including models of the electric components, wiring, …), software designs (IEC 61131-3 function blocks, structures, …), etc. are all modeled. The semantics of the models are well defined: they are expressed using the logic-based Web Ontology Language (OWL). This allows us to use off-the-shelf Semantic Web “reasoners” to verify the models, and to draw new conclusions that are useful for more in-depth analysis of the designs. The benefits of the information models become very apparent when applied to complex control systems such as those of a telescope. By querying the models, and feeding the query results into a template system, we can generate web-based documentation for all aspects of the telescope, or even source code for the PLCs and for the SCADA level. Fig. 3 shows, for instance, the results of a custom query that selects all I/O module types in the models, their manufacturer and their description, and counts their instances. Fig. 4 shows how predefined queries and predefined web templates can be used to document the system. It shows how we can navigate between the systems/requirements model, the electric model, and the software model simply by clicking on the hyperlinks, thereby “following” the links between the elements of the information model. OPC UA comes into the picture when information must be exchanged, for instance between the PLC level and the SCADA level. Essentially, since all our software is modeled, we can generate source code from these models for both the OPC UA server-side and OPC UA client-side:
- The OPC UA server-side consists of Beckhoff TwinCAT 3 embedded systems. We use them to import the PLCopen skeleton code that was generated from our software models, “glue” this generated code together with custom PLC code, and expose the resulting software via the built-in TwinCAT OPC UA server. The embedded systems thus expose the very same IEC61131-3 model that we originally defined in our knowledge-based system, as an OPC UA information model.
- For the OPC UA client-side, we only generate some Python stub code based on our OPC UA framework UAF. Client-side applications can therefore easily communicate with the server-side, as both were generated according to the same information model.
While future smart systems will have to expose more contextual information than our embedded systems are currently doing, experience has learned us that well-defined information models can offer significant added value to control systems today. Essentially, they allow us to take full advantage of the technologies that are currently available. Further progress should therefore not only be expected from the “technical side” of the story. It’s the semantics, that really matter.
More information about this research project can be found here, or can be obtained by contacting the author.

Fig. 2: The Mercator Telescope.
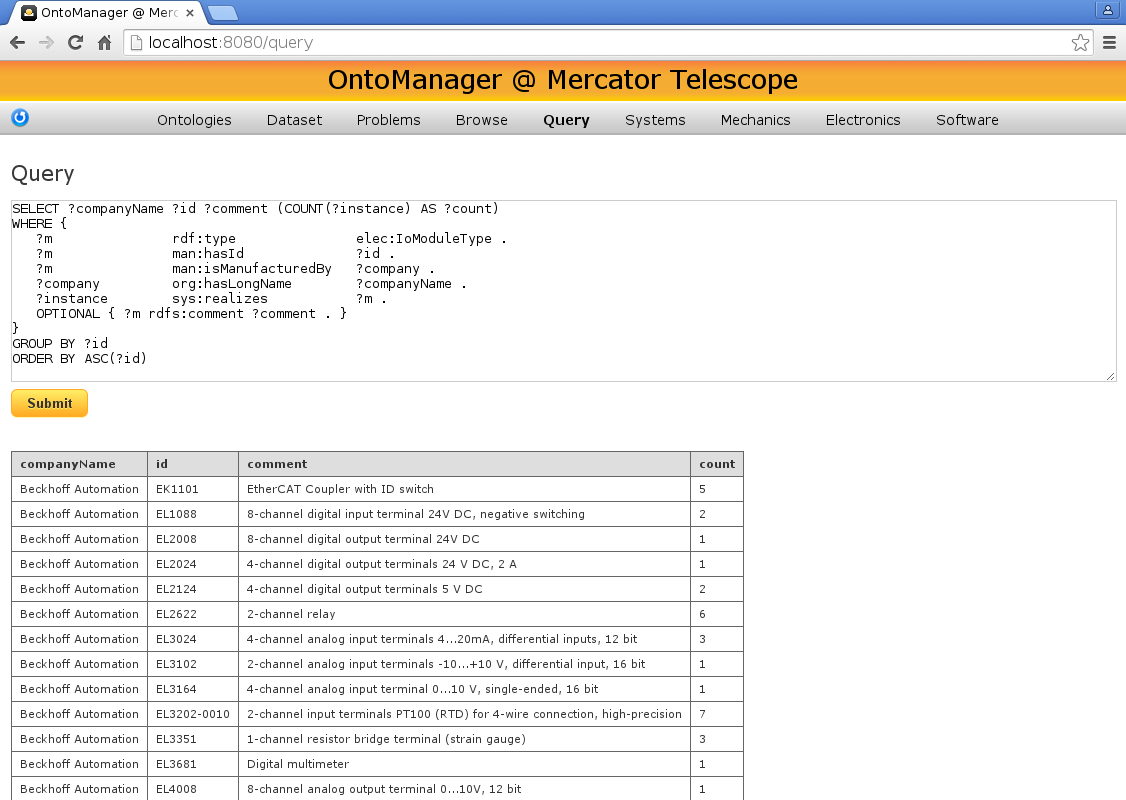 Fig. 3: A custom query, showing all I/O modules in the information model.
Fig. 3: A custom query, showing all I/O modules in the information model.
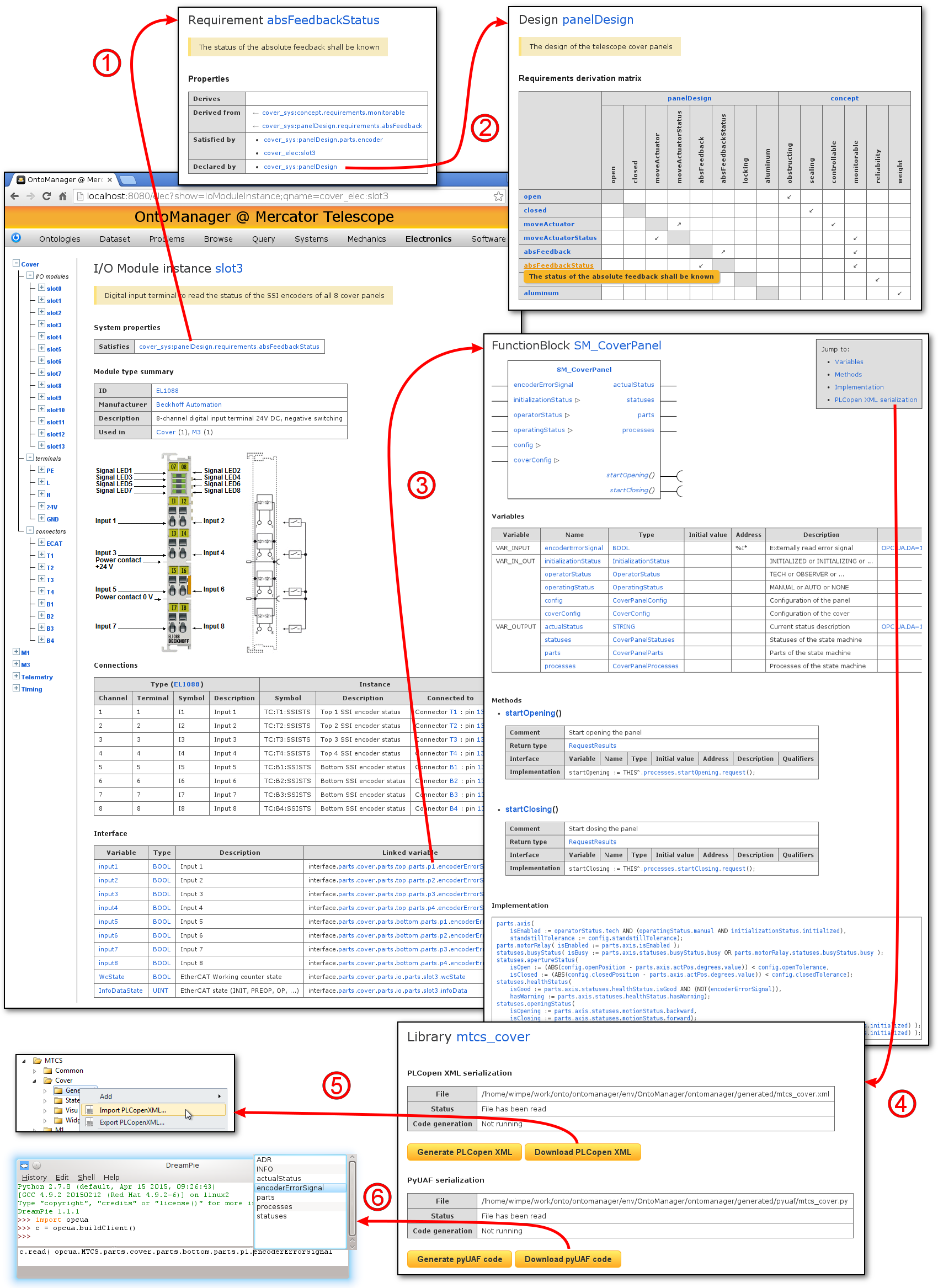 Fig. 4: Web-based documentation automatically generated from the information model
Fig. 4: Web-based documentation automatically generated from the information model
{kind=link}