SPONSORED BY: Software Toolbox

Downtime isn’t just an inconvenience. It can halt operations, which could result in lost production, missed data, delayed decisions, and costly recovery. Even routine maintenance becomes disruptive without failover strategies, leading to financial losses, wasted resources, compliance risks, and reduced trust in system reliability.
Redundancy is a tool used in implementing high-availability strategies to minimize these risks by providing backup servers, clients, and network paths. If one component fails, another takes over, preserving visibility into data, alarms, and logging of historical data. The result: seamless continuity, resilient operations, and protection against the high costs of downtime.
Simplifying Redundancy with OPC UA
While the OPC UA specification includes an optional standardized method for redundancy, it is not yet widely implemented. Until then, users need solutions they can use today with OPC UA systems, but also OPC Classic and other data sources, which we will refer to here as “vendor-implemented OPC UA redundancy.” Solutions for vendor-implemented OPC UA redundancy should easily integrate with existing OPC UA systems that haven’t yet implemented the specification provided methodology. They should also leverage the fact that OPC UA makes redundancy far easier than with older OPC Classic systems where DCOM was required. Solutions should make configuring redundant servers, clients, and connections straightforward and reliable.
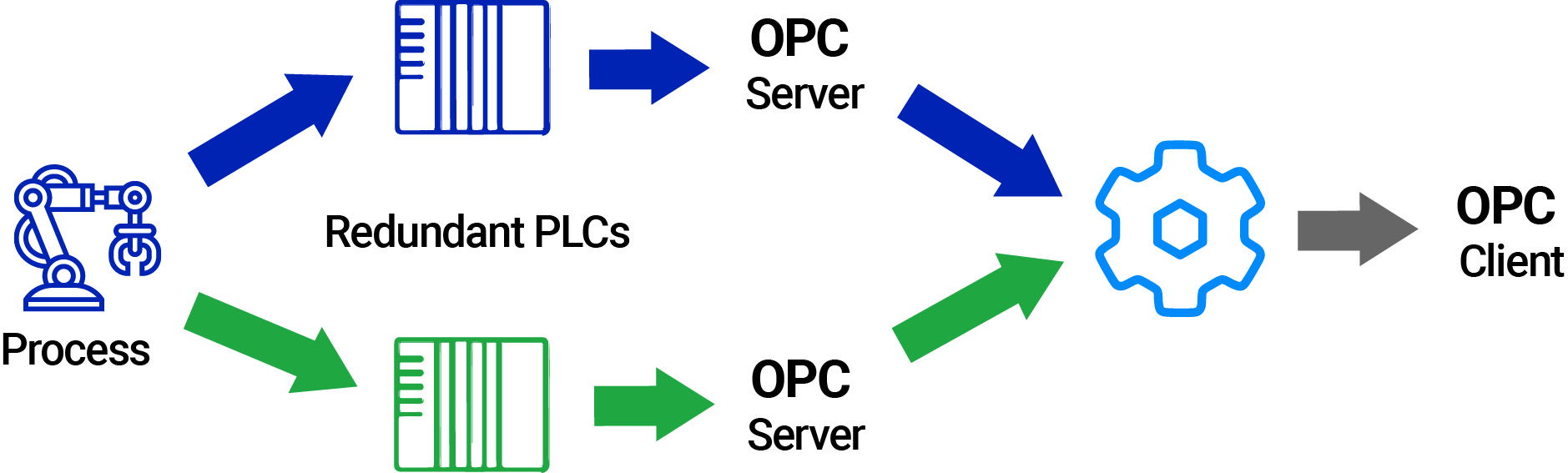
Cogent DataHub® (“DataHub”) is a vendor-implemented OPC UA redundancy solution that meets these requirements. DataHub delivers a practical, proven approach to redundancy as part of a high availability strategy. It sits between your servers and clients, securely handling failovers and reconnections automatically between a wide variety of data sources and destinations, not just OPC UA. The solution also supports tunneling to extend redundancy into mixed environments that include both OPC UA and OPC Classic.
The result is resilient operations that stay online — without relying on whether or not your different platforms all support the same spec-level features or even use OPC UA.
Redundancy with OPC UA vs. OPC Classic
A key reason why OPC UA stands out is how much simpler redundancy is when compared to OPC Classic. With OPC Classic systems, redundancy required OPC DA Servers communicating across a network with DCOM, requiring complex security settings, fragile configurations, and unreliable failover behavior. Even a well-planned redundant setup could be difficult to maintain and troubleshoot with OPC Classic.OPC UA eliminates those challenges. OPC UA is cross-platform, firewall-friendly and enables a clean, reliable way to configure redundant servers, manage client connections, and ensure automatic reconnections. As an added bonus, OPC UA also adds the benefit of built-in security features like encryption, authentication, and granular access control.
But what if you still rely on OPC Classic systems or have a mix of technologies? The DataHub solution can also help bridge that gap by converting OPC Classic to OPC UA but also securely tunneling it , granting you all the benefits that come with OPC UA. This means all your client connections — whether to Classic or UA servers — can be localized under one unified, resilient UA interface. The result is a streamlined architecture that extends modern redundancy benefits to legacy systems without forcing a full rip-and-replace.
Redundancy Terminology
For readers who may be new to redundancy in OPC systems, here are some concepts that are important to understand.
- Server Redundancy – Multiple OPC servers maintain data access. If the primary server fails, clients automatically switch to the backup, ensuring uninterrupted access to information.
- Connection Path Redundancy – Clients maintain multiple secure communication paths. If one network path becomes unavailable, communication continues seamlessly over another.
- Transparent Failover – In configurations where failover is handled entirely by the server or middleware, clients remain unaware of the switch. Eliminating the need for custom failover logic while maintaining continuous operations.
Best Practices for High Availability
High availability depends on many factors, including a well-designed redundancy architecture. Implementing redundant servers, network paths, defined roles, and tested failover procedures ensures minimal downtime, data integrity, and continuous operations even during unexpected failures.
Key Elements
- Redundant servers and communication paths – Ensure backup hardware servers, software and alternate network paths are established to eliminate single points of failure and are ready to take over instantly if a primary system fails.
- Load balancing for performance and failover – Distribute workloads across servers to prevent bottlenecks and enable smooth failover when needed.
- Clear role assignments (primary vs. secondary) – Define which server is active and which is on standby to avoid conflicts and confusion during switchover.
- Continuous health monitoring of nodes and networks – Track system status in real time to detect issues early, reducing the risk of unexpected downtime.
Common High Availability Mistakes in Industrial Systems
Redundancy alone doesn’t guarantee high availability. There are other factors to high-availability success that we don’t have space to discuss here, but we’ll highlight a few. Skipping testing, relying on manual processes, or assuming IT tools meet OT system needs are common mistakes we see. Addressing these pitfalls is essential to ensure redundancy truly supports high availability and system resilience.
- Assuming IT redundancy tools (like Nutanix) sufficiently cover OT system needs – While these tools assure availability of computing infrastructure, virtual machine failover does not guarantee industrial applications or OPC UA connections remain online. Industrial systems require specialized failover handling to maintain continuity.
- Relying on manual switchover processes – Human intervention introduces delays and errors, especially during emergencies. Automated failover ensures a faster, more reliable response.
- Skipping regular failover testing – Redundancy only works if validated. Periodic testing under real-world conditions ensures failover logic, client reconnections, and data continuity function as expected.
- Overlooking client reconnection behavior – Even with seamless server failover, clients must automatically reconnect and resume subscriptions. Poorly managed client failovers can cause dropped data, missed alarms, or performance issues if set up incorrectly.
Looking Ahead: Guidance for Clients
Before implementing redundancy, it’s important to focus on impact and priorities:
- Which systems are most critical? Identify servers, devices, and applications whose failure would disrupt operations most.
- What downtime costs the most (production, compliance, safety)? Assess financial, regulatory, and safety implications to guide investment.
- Which architecture pieces are single points of failure? Map infrastructure to uncover components, network paths, or software dependencies that could cause cascading failures.
Why Work with a Solution Provider?
Systems integrators and technology solution providers can help map risks, evaluate trade-offs, and align redundancy design with business objectives. Working as partners, they bring expertise in integrating legacy and modern equipment, avoiding overengineering and ensuring redundancy is implemented effectively and incrementally.
Where Redundancy is Evolving
Redundancy is evolving beyond simple backup systems. New approaches are smarter, faster, and more scalable, helping operations stay resilient in a connected world.
- Hybrid redundancy (edge + cloud models) – Combining on-premises systems with cloud-based redundancy ensures local resilience while providing enterprise-wide visibility and centralized monitoring.
- AI-driven predictive failover – Machine learning can detect early signs of system degradation, enabling proactive failover before failures occur.
- Incremental and scalable redundancy – Organizations will increasingly adopt modular approaches, starting with critical assets and expanding redundancy as operational needs and budgets allow.
Software Toolbox Solutions: Cogent DataHub & OPC Router
As our company name implies, we deliver a variety of solutions for solving a variety of OT, IT, and ET data integration, and we recognize our solutions need to incorporate support for capabilities that enable high availability, such as redundancy. We’ve covered DataHub here but want to mention another tool that solves different problems and supports redundancy.
Cogent DataHub enables implementation of real-time secure connection redundancy and in complex IT network architectures, between OPC servers and clients across multiple standards including Alarms & Events/Conditions, but also non OPC data. Acting as a single real-time connection point, DataHub manages failovers and reconnections automatically, keeping data flowing even if a server or network link goes down.
OPC Router is a visually configured event-driven workflow software tool with configuration templates for scalability that is well suited for environments where redundancy needs to be combined with workflow logic, advanced OPC UA standards support, and enterprise integration. Its trigger-based design enables data transfers to be retried, rerouted, or redirected when a source becomes unavailable, ensuring that mission-critical flows into ERP, MES, databases, or cloud platforms are not disrupted.
Take the Next Step
Contact our solutions team today for a consultation and discover how Cogent DataHub or OPC Router can help you implement OPC UA redundancy tailored to your systems and priorities.
Interested in More Information
Explore additional insights on industrial data integration, redundancy, and high-availability solutions below.
- How to Achieve Software Level Redundancy & High Availability – in Industrial Data Integration Applications
- Got OPC Redundancy Questions?
- How to Simplify OPC Server Redundancy with Cogent DataHub
- OPC Router Application High Availability & Data Connection Redundancy
About Software Toolbox Software Toolbox, founded in 1996 and a Charter Member of the OPC Foundation, was the world’s first industrial automation software company focused on software that leverages open standards for OT, IT, business and now cloud systems. Through our early leveraging the internet for global support reach we’ve built an installed base on every continent (yes even the South Pole Station!), they are known for their technical expertise across their variety of solutions that empowers success and reduces the risk of multi-vendor applications. Our raving fan users that trust our brand are a clear testament to the value we provide through the Software Toolbox way.
DATAHUB, WEBVIEW, Cogent DataHub, OPC DataHub, Cascade DataHub, DataHub WebView, Gamma are either registered trademarks or trademarks of Real-Time Innovations International LLC, and licensed to Cogent Real-Time Systems., in Canada, the United States and/or other countries. Software Toolbox uses these trademarks under the terms of its agreements with Cogent Real-Time Systems.